Reactive Extensions make it very easy to create a processing pipeline, especially when some stages on that pipeline are naturally asynchronous operations. This is because just like a Promise (or Task in .NET) can be seen as the asynchronous version of anything that produces a value, the Observable pattern can be seen as the asynchronous version of the Enumerable pattern.
So the following code seems pretty straightforward and easy with Rx:
getListOfLocations()
.flatMap(loc => download(loc))
.map(resource => unzip(resource))
.map(bigText => heavyProcessing(bigText))
.subscribe(registerResult)
We're essentially fetching resources from the internet, unzipping and processing them. The fact that download is asynchronous fits nicely with Rx. But this simple chain might yield a problem: what happens if heavyProcessing becomes the bottleneck?
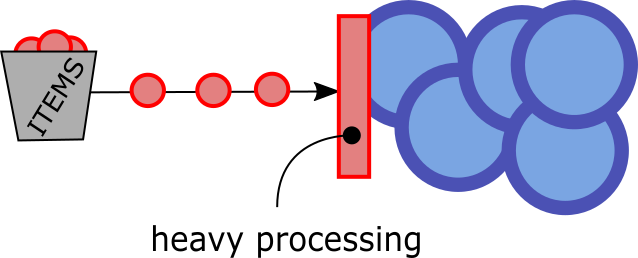
If heavyProcessing becomes the bottleneck, we'll still be downloading and unzipping content (into memory) but we'll have to queue it up because the processing stage will only observe one item at a time. This means we'll probably run out of memory fast, which makes no sense because we should have full control on the rhythm under which we download the resources or unzip them.
There are some Rx operators that aim at throughput control, like throttle or debounce, but none of them is very useful here, as both end up discarding items when they're observed too fast. In this example we're not interested in discarding any item. We just want to queue up work where we can handle it and then control the rhythm at which we emit items to make sure we won't drown the system under heavy load.
It's still possible to achieve such a solution with Rx by using the following pattern:
- Create an observable to represent work tokens.
- Use these items to control throughput by either:
- Mapping work tokens into work like
tokens.map(t => /* disregard t and get next location */) - Using tokens to buffer up work items where you can
getListOfLocations().zip(tokens).map(pair => pair.first)
- Mapping work tokens into work like
- Put a step down the Rx operations chain to emit tokens when resources become available (eg: for each item you process)
- Start the whole chain by feeding a few tokens into it (or just one if you're processing one item at a time)
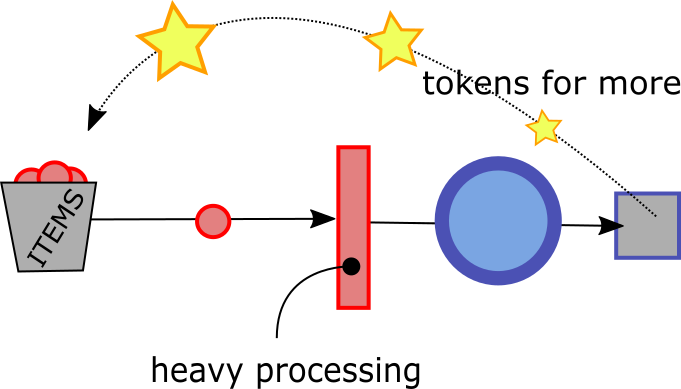
This strategy will only work very well for scenarios where you can control the initial feeding of items into the observable stream, such as controlling the rate at which you read lines from a file you already have in disk. For other scenarios where you have no control over the events that trigger the stream (such as a server taking requests from clients or a user clicking or typing) this strategy can still apply as it enables you to queue items at a stage of the pipeline where they don't need big resources (before turning URLs into downloaded content, or before unzipping that downloaded content into something bigger). Of course, in this latter case, the queue can still grow up too much. But then there's no miraculous solution. To solve such a case, you'll have to consider either discarding work items (through throttling or debouncing) or adding more horsepower into the system.
Note that these controllable observables (for the lack of a better name) are neither hot observables (which emit events despite being subscribed or not) nor cold observables (which only start emitting events once subscribed).
See it in action!
Conclusion
Reactive Extensions provide a very good way of turning asynchronous processing pipelines into readable code that's easy to reason about. However, when dealing with asynchronous processing, it's always good to take care of understanding how the system's we're building will queue up tasks or attempt to do them all in parallel, and what that will mean regarding system resources. A library such as Rx can be a great help to design a good system, but it isn't in itself an all-in-one solution nor a replacement for thinking about a good architecture.